
We’re (a group of friends) building a search engine from scratch to compete with DuckDuckGo. It still needs a name and logo.
Here’s some pictures (results not cherrypicked): https://imgur.com/a/eVeQKWB
Unique traits:
- Written in pure Rust backend, HTML and CSS only on frontend - no JavaScript, PHP, SQL, etc…
- Has a custom database, schema, engine, indexer, parser, and spider
- Extensively themeable with CSS - theme submissions welcome
- Only two crates used - TOML and Rocket (plus Rust’s standard library)
- Homegrown index - not based on Google, Bing, Yandex, Baidu, or anything else
- Pages are statically generated - super fast load times
- If an onion link is available, an “Onion” button appears to the left of the clearnet URL
- Easy to audit - No: JavaScript, WASM, etc… requests can be audited with F12 network tab
- Works over Tor with strictest settings (official Tor hidden service address at the bottom of this post)
- Allows for modifiers: hacker -news +youtube removes all results containing hacker news and only includes results that contain the word “youtube”
- Optional tracker removal from results - on by default h No censorship - results are what they are (exception: underage material)
- No ads in results - if we do ever have ads, they’ll be purely text in the bottom right corner, away from results, no media
- Everything runs in memory, no user queries saved.
- Would make Richard Stallman smile :)
THIS IS A PRE-ALPHA PRODUCT, it will get much MUCH better over the coming months. The dataset in the temporary hidden service linked below does not do our algorithm justice, its there to prove our concept. Please don’t judge the technology until beta.
Onion URL (hosted on my laptop since so many people asked for the link): ht6wt7cs7nbzn53tpcnliig6zrqyfuimoght2pkuyafz5lognv4uvmqd.onion
I love the notion. The marketing “better than DDG” is a little janky. Perhaps consider a positive statement, like “finally find what you’re looking for”.
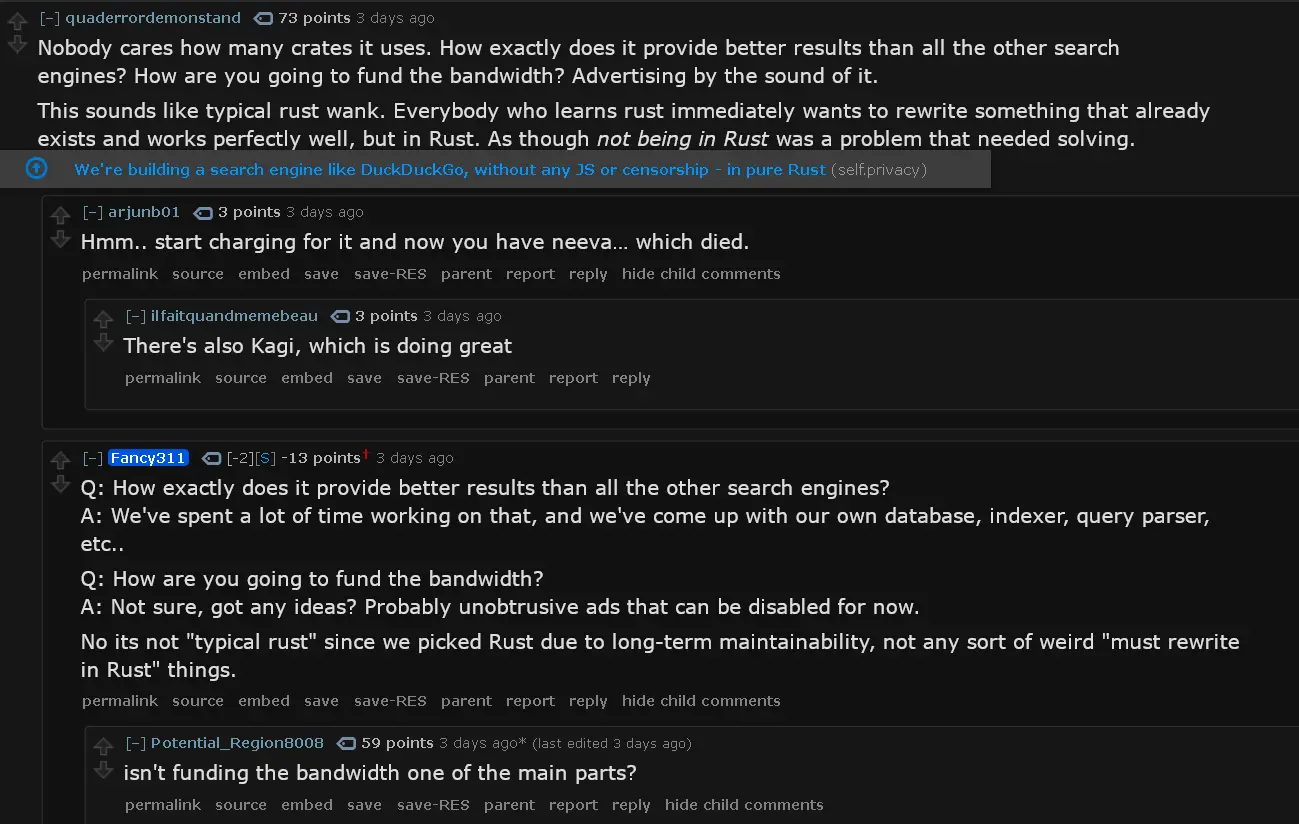
This is a crowded landscape. I’ve been here since Gopher and seen plenty of services come and go. With that in mind, here are some questions you might want to consider:
How does it compare with products like SearXNG, specifically their ecosystem of plug-in search types?
How do you plan to pay for it?
How do you expect to protect the index against spam?
How will you scale it to a global audience?
How will you handle language?
Good luck!
To answer your questions in order:
- We have our own index, its not a shitshow of mixed results like Searx tends to be. this also means that we’re not chasing breaking changes of some larger engine when they decide they dont want us, like Twitter did to Nitter, and Bing did to Searx.
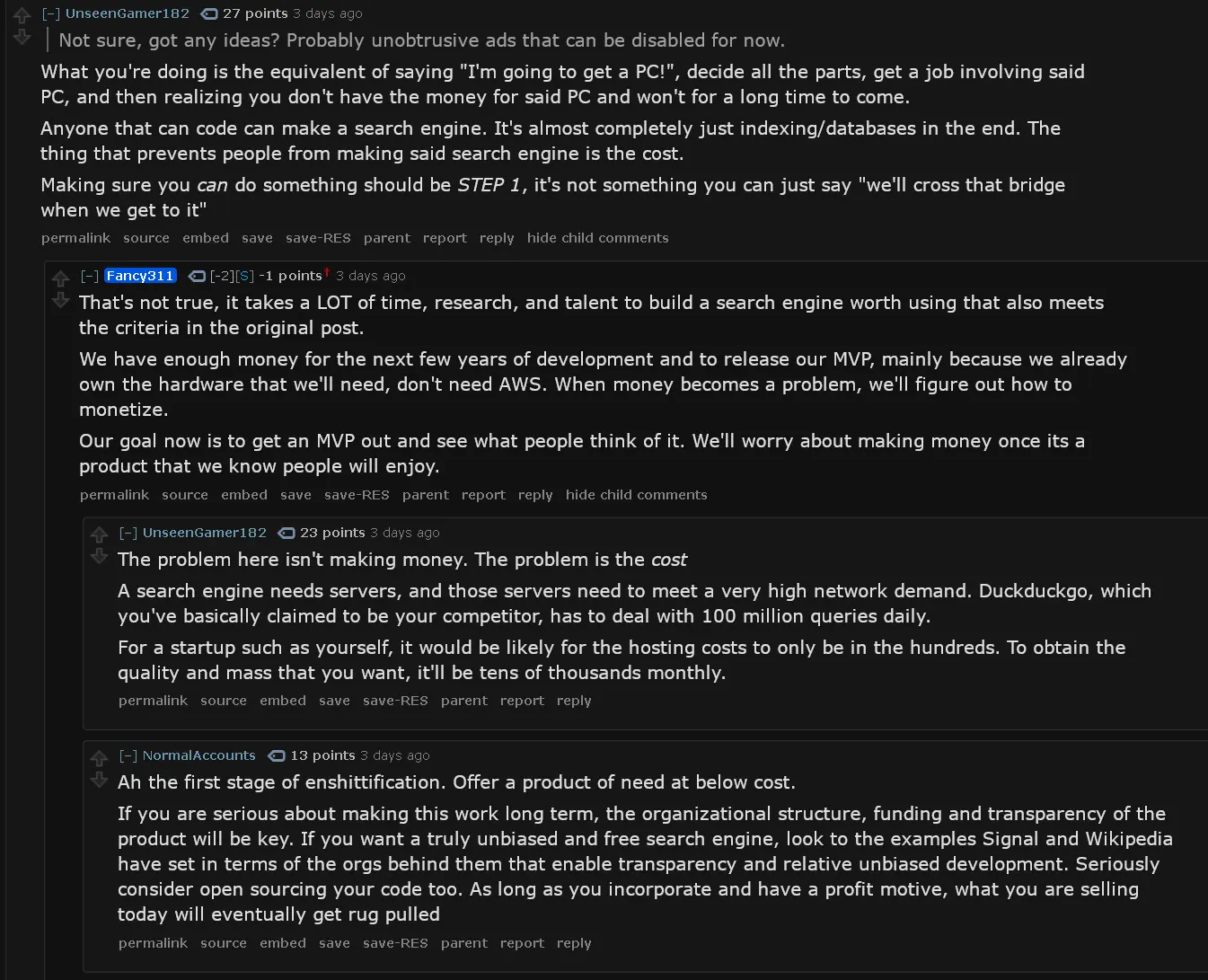
- We don’t know how to monetize. Ads are the only option that we know of, donations do not work at all, as proven by my previous projects.
- We’ve already got spam prevention and removal measures in place, but I won’t discuss them.
- We don’t know how to scale it since its centralized by design and the frontend and backend are tightly integrated, largely because the frontend is largely generated on the fly by the backend. Maybe host a copy for each region we’re aiming to acquire users from?
- Our engine already understands 5 languages, and we hope to expand to CJK languages soon.
We don’t know how to monetize. Ads are the only option that we know of, donations do not work at all, as proven by my previous projects.
A subscription-based model might be the only viable one, since ads will inevitably lead to a conflict of interest and voluntary donations are mostly a no-go. The problem is that people are so used to the notion that everything is “free” that many are convinced that online services should always be free and balk at the idea of paying for anything.
Personally I pay for Kagi which has been decent enough
I mean, a search engine is literally the last thing on the internet I’d pay a subscription for. In a world where literally everything else nickels-and-dimes us for subscription service, search engines, torrent trackers, game modders who paywall their mods, and other kitschy non-essentials are literally the first things to get shuffled off the monthly budget.
If we weren’t in such a deep recession that I pay as much a week for my gas as I do my groceries, with rent and ACTUAL bills eating the majority of what’s left, I’d feel a bit differently; but if wishes were horses, we’d all ride. I literally had to start growing my own green rather than buying it, the economy’s so shit.
The problem is that people are so used to the notion that everything is “free” that many are convinced that online services should always be free and balk at the idea of paying for anything.
A huge part of that is that most people don’t consider privacy concerns to be a cost. All they factor into their evaluation is whether it costs them actual money.
Personally I pay for Kagi which has been decent enough
Whats “decent enough” mean? I’ve been curious and you’re the only person I’ve known who pays for it.
I pay for it, the results are quality and the fact that my brain doesnt have to sift through ad results and can just look at the real data is so nice. Additionally, they have a large number of “lenses” which can change the scope of your search. For example, they have a lens for searching lemmy as well as lenses for the “small web”, which filters out all the results from massive corporate websites and gives way more personal project sites and the like.
All in all I’m a fan.
Seconded this. Been paying for a long time now, no regrets.
I personally like a lot the gazillion bangs also available, the personal up/downranking/blocking of websites and their quick answer is often fairly good (I mostly use it for documentation lookup). The lenses are definitely the best feature though, especially coupled with bangs. I converted even my wife who really loves it.
I never thought id pay for Kagi and that paying for a search engine was ridiculous. Then I kept seeing loudly positive feedback from reputable people in my circle and tried the trial.
I pay for it and never have the “I only ever use !g on duckduckgo” problem.
Sorting by web pages with least ad trackers is a cheat code to find old style websites with people sharing knowledge for knowledge’s sake rather than profit.
Just my two cents, but I keep trying it out and I have not seen anything good enough to warrant paying for it. And I am not against paying for privacy, I pay Proton.
You could let people host their own as a method of scaling. But that limits it to geeks like us.
Use kubernetes and let it scale and pay for hosting on cdns.
Ahh, you’re the guys who posted over in reddit before your thread got locked that think it’s a good idea to promote Russian propaganda equally with Ukrainian content, because you don’t want to ‘Take sides’ politically. Closed source too, so that’s pretty much a dealbreaker right there, especially for Privacy focused users. We’ve been abused by closed source software for far too long to trust anything less.
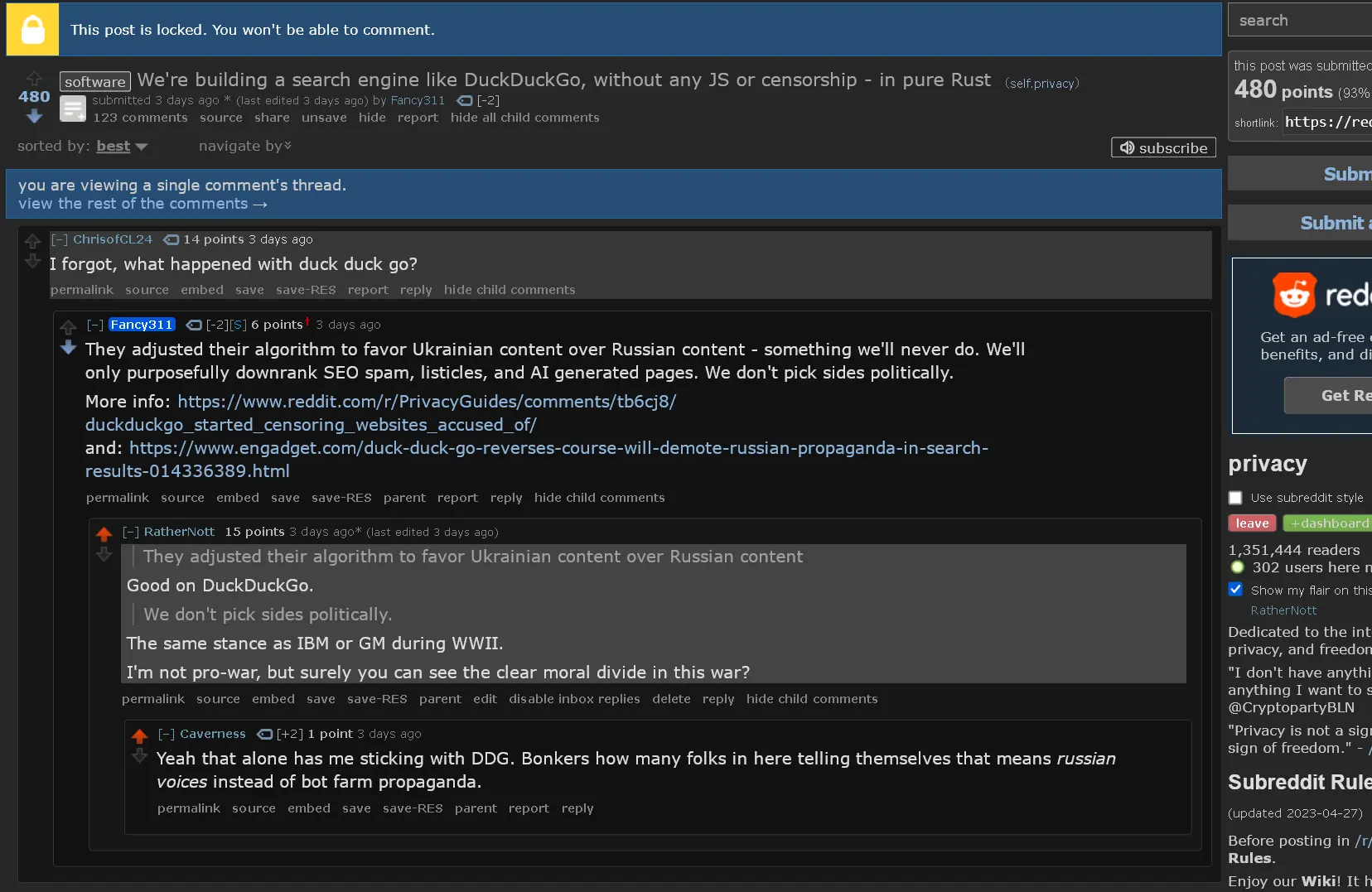
You also have absolutely no plan on how to monetize, as others have said in this thread already.
I certainly won’t be supporting you, not with those values.
Thank you for taking the time to point this out.
I applaud your efforts and I admire your idealism.
Unfortunately, the minute you get the bill from your internet provider, you’ll need to find a way to pay for it, and your good intentions will instantly dissolve in the murky realities of modern corporate surveillance capitalism.
But at least while you haven’t gotten your first bill, it’s refreshing to watch your enthusiasm.
pay for it
I wonder what a distributed search engine would look like. Basically, the index would be sharded across user computers, and queries would hit some representative sample of that index. This means:
- hosting costs are very low - just need a way to proxy requests to the network
- search times should improve as more people use the service
- no risk of the service logging anything - individual nodes don’t need to know who requested the data, just who to send the response to
My biggest concern is how to build the index, but if OP is willing to share that, I might start hacking on a distributed version.
Don’t start new; contribute to what already exists: https://en.wikipedia.org/wiki/YaCy
Awesome! That’s pretty much exactly what I’m looking for, though I’m interested to see how easy it is limit certain peers to certain functions. Not everyone has resources to crawl and index pages, but a lot of people can store the index.
I’m interested in having client-side web storage, so you can participate in the network by just having the search page open (opt-in of course).
I’m honestly not actively working on it, but if OP provides the database and/or crawler, I’ll do some research on feasibility.
This is really neat and I’m just hearing about it after over twenty years of development. I need to try it out, thank you. How do you stay in the know about this kind of stuff? I’m curious about all the cool stuff out there I wouldn’t even know I’m curious to find.
How do you stay in the know about this kind of stuff?
By being terminally online, I guess?
More concretely, I’ve spent (probably too much) time on Slashdot, Reddit and now Lemmy over the years (subscribed to Free Software and privacy-related communities in particular). Also, looking through sites like https://awesome-selfhosted.net/ and https://www.privacytools.io/, wiki-walking through articles about Free Software projects on Wikipedia, browsing the Debian repositories, etc.
I’m sure there are plenty of things I haven’t heard of either, though.
How do you stay in the know about this kind of stuff? I’m curious about all the cool stuff out there I wouldn’t even know I’m curious to find.
I was going to mention YaCy as well if nobody else was, so I can chip in to this somewhat. My method is to keep wondering and researching. In this case it was a matter of being interested in alternative search engines and different applications of peer to peer/decentralized technologies that led me to finding this.
So from this you might go: take something you’re even passingly interested in, try to find more information about it, and follow whatever tangential trails it leads to. With rare exceptions, there are good chances someone out there on the internet will also have had some interest in whatever it is, asked about it, and written about it.
Also be willing to make throwaway accounts to get into the walled gardens for whatever info might be buried away there and, if you think others may be interested, share it outside of those spaces.
I wonder what a distributed search engine would look like.
Isn’t that what Searx is/can be?
https://en.wikipedia.org/wiki/Searx#Instances
I admit it’s not something I’ve looked closely at.
No, Searx is a metasearch engine that queries and aggregates results from multiple normal search engines (Google, Bing, etc.)
A distributed search engine would be more like YaCy, which does its own crawling and stores the index as a distributed hash table shared across all instances.
Ah thanks - appreciate the clarification.
Exactly. The main difference I would bring is a web client that hooks into the network, and perhaps an alternative client (e.g. I’m interested in Tauri, so I may rewrite part of the BE to Rust).
But I’m probably not going to start on this project on my own. DDG is good enough for now, so I’m putting my efforts elsewhere.
i feel that decentralized search is an extremely valuable thing to start thinking about. but the devil is in practically every one of the details.
Yup. Even if you trust all your peers (which isn’t reasonable), there’s still a ton of practical issues that need to be resolved:
- pagination with a different set of peers
- moderation of CSAM and whatnot
- outdated peers and stale data
- how much data and where are results reduced
It’s a really complex problem without getting p2p involved, and p2p just adds a ton of other problems.
So I’m probably going to stick with building my Reddit clone, which I think is simpler (search doesn’t need to happen at the start).
My thoughts exactly when reading this.
I believe people when they claim to develop free software. Often because it’s software the dev wants for themselves anyway and they’ve merely elected to share it rather than sell it. The only major cost is time to develop, which is “paid” for by the creation of the product itself.
You (OP) are proposing a service. Services have ongoing fees to run and maintain, and the value they create goes to your users, not you. These are by definition cost centers. You will need a stable source of funding to run this. That does not in any way mix with “free”. Not unless you’re some gajillionaire who pivoted to philanthropy after a life of robber baroning, or you’re relying on a fickle stream of donations and grants.
You indicate in other comments you will not open the source of your backend because you don’t want it scooped from you and stealing your future revenue. That’s fine, but what revenue? I thought this was free? What’s your business model?
It sounds like what you want to do here is have a free tier anyone can use, supported by a paid tier that offers extended features. That’s fine, I guess. But if you want to “compete with DuckDuckGo”, you are going to need to generate enough revenue to support the volume of freeloaders that DDG does. If your paid tier base doesn’t cover the bill, you will need to start finding new and exciting ways to passively monetize those non-revenue-generating users. That usually means one or more of taking features away and putting them behind the paywall to drive more subscriptions, increasingly invasive ads on the platform, or data-harvesting dark patterns.
Essentially what I’m saying here is, as-proposed, the eventual failure and/or enshittification of your service seems inevitable. Which makes it no better than DDG long term.
It is, at any rate, a very intriguing project.
For now we’re going to host on residential connections, and if any ISPs ban us, we’ll just find other ISPs
Yeah, when you say stuff like this, it shows how woefully unprepared you are for the realities of this. You can’t scale, can’t self host for long, don’t see a way to pay for this… When I can already pay Kagi for a fully working, excellent service, why would I choose you? This is guaranteed to crash and burn the moment your ISP tells you you can’t run a commercial grade server through your residential connection. They’ll either cap your bandwidth to unusable levels or disconnect you entirely. If you’re lucky you’ll have 1 or 2 other options to choose from, whom will blacklist you shortly after. Then, after you’re burnt through all the “easy” ways to host, all you’ll be left with is professional grade services that you admit you can’t afford.
Also, you make zero mention of user privacy. So what happens when you get your first subpoena? Or before that, why should I trust you with my data in general? What policies do you have in place to ensure my legal rights are protected? Do you even know what the legal rights are per state/country and how the location of where someone connects from impacts you? How are you gonna handle visitors from the EU with GDPR?
Nifty idea, but way too much “I’m gonna single handedly reinvent the wheel” vibes.
Would make Richard Stallman smile :)
If this is a closed source project, that statement doesn’t work even as a joke.
However, the screenshots looked good. :)
Richard Stallman cares more about what is running on your computer than he does about what is running on a server.
Fair point though
That comment is there specifically to drive engagement up with all of the people correcting me in the comments.
Ah, the 4chan method of engagement, right?
Lying is a great way to get engagement in the post, and then see your project crash and burn.
I’m only interested in your rant in a few weeks when nobody cares.
Fair!
I got so excited reading this post, but as I read that the project will not be open source, my excitement immediately faded away
They won’t open source it because the rust code is very likely a joke. They are proud of just using two dependencies, don’t know that their “statically generated” stuff is actually called server side rendering and are hosting this stuff on a fuckin laptop.
It’s probably a project that will teach them a lot. But in practice their implementation is worthless to everybody else because they are obviously completely inexperienced.
That said, that project is likely not worthless to them because they will probably learn a ton of stuff why it’s hard to build a search engine.
- Would make Richard Stallman smile :)
source (code)?
Closed source
Closed source
Yeah, not sure how they can include that line about Stallman with a straight face. That’s almost libel.
https://lemmy.world/comment/8535938
They just said that to “drive engagement”.
Agreed
ew
Please post when you’re ready for beta waters. I’m looking forward to seeing it.
Closed source and privacy most of the time don’t mix. Or more so the privacy crowd and closed source doesn’t mix. You won’t see much support for your project if it remains like that. Maybe a source available but still closed license would be better. Think about your monetization strategy a bit as well. Consider having premium features and make it a freemium product.
Wow this is great!
if you are using your own index, I think you could use a more economical approach to fight the spam bullshit of the modern web.
- instead of using badness enumeration, crawling everything and filtering malware, use an opt-in principle
- have a community method of gathering new trusted websites
- use websites internal search functions to get more results
- use categories to split up the websites, reinventing what people should find: general, news, navigation, science, politics, IT, technology (not code), art, music, philosohy, …
- have an app or submission website where users can submit new websites, and some form of community control over it (kinda censorship but in a good way)
This could fix the web as it currently is, by rethinking what should be found, pushed etc. Rating websites by quality could also be helpful.
Also if you support payments in crypto or cash, there should be no problem to make it paid.
Looking at the picture, why are you guys using Brave?
I don’t know DuckDuckGo, but what’s the purpose of trying to compete with it? This is not a rhetorical question. Is there something wrong with DuckDuckGo, something you feel you can do better, or are you just making a competitor for the principle?
Not OP, but there is value in having competition. DDG is just a bing front-end. The big search engines have a major problem with the quality of results going down, as the internet is SEOd to death. The companies behind these engines don’t seem to be very eager to fix it, they are just hoping to replace them with AI. We’ve also seen how these engines have been turned into ad platforms, which changes the incentives… Instead of ranking quality, they are ranking who pays more.
Taking a different approach to ranking results that isn’t ad driven, that can punish AI generated content and low quantity results would bring a huge value.
DDG is just a bing front-end.
That is wrong. Yes there are licensing the bing search database but it is not the only one they use. They have their own crawler too.
“Only two crates used”. What’s great about reinventing the wheel? A closed source project with big claims trying to reinvent everything from scratch. Nice project 🤣
Every dependency is a security hole
Pages are statically generated
Can you elaborate on that? To me, statically generated would mean you are pre-rendering a html page for every possible search, which doesnt sound possible? Do you mean that its all server side generated (at the time of search)?
I think he means pages are presented as static html+css pages, generated dinamically on the back end
Only two crates used - TOML and Rocket (plus Rust’s standard library)
This seems like a bit of a weird approach. There’s lots of existing nice Rust crates to build with, why use such a minimal approach?
Also Rocket has essentially been superceded by more mature frameworks like Axum.
Its about reducing attack surface and risk by minimizing dependencies
Reducing the attack surface by not using well established and battle tested crates but reinventing the wheel inside this closed source project 🤣
Well that’s a bit of a double-sided sword. Libraries also includes lots of failsafes built in that you’ll need to implement yourself then. And you’ll need to be confident that you don’t implement security issues in your own code instead of relying on widely used libraries. But it makes sense if you’re worried about supply chain attacks.
That’s a neat project.
You can be proud of your work 😊But I for one won’t donate to your cause, as the software seems to be closed-source, and I already have DuckDuckGo & Google for my searching needs.
I genuinely believe that the only viable niches for new search engines are environmentally-friendly (e.g. Ecosia) or open-source.
Literally no one will pay for a closed-source search engine.
But I like your tech stack, and your project’s looking good.
One more thing: You claim to be against censorship; how will you combat spam & SEO farming?



















