
Trying something new, going to pin this thread as a place for beginners to ask what may or may not be stupid questions, to encourage both the asking and answering.
Depending on activity level I’ll either make a new one once in awhile or I’ll just leave this one up forever to be a place to learn and ask.
When asking a question, try to make it clear what your current knowledge level is and where you may have gaps, should help people provide more useful concise answers!
You must log in or register to comment.
Knowledge level: Enthusiastic spectator, I don’t make or finetune llms, but I do watch AI news, try out local llms, and use things like Github copilot and chat gpt.
Question: Is it better to use code llama 34b or llama2 13b for a non coding related task?
Context: I’m able to run either model locally, but I can’t run the larger 70b model. So I was wondering if running the 34b code llama would be better since it is larger. I heard that models with better coding abilities are better for other types of tasks too and that they are better with logic (I don’t know if this is true I just head l heard it somewhere).
I feel like for non coding tasks you’re sadly better off using a 13B model, codellama lost a lot of knowledge/chattiness from its coding fine tuning
THAT SAID it actually kind of depends on what you’re trying to do, if you’re aiming for RP don’t bother, if you’re thinking about summarization or logic tasks or RAG, codellama may do totally fine, so more info may help
If you have 24gb of VRAM (my assumption if you can load 34B) you could also play around with 70B at 2.4bpw using exllamav2 (if that made no sense lemme know if it interests you and I’ll elaborate) but it’ll probably be slower
What can I run on a 1080ti and how does it compare to what’s available in general?
On Huggingface is a space where you can select the model and your graphics card and see if you can run it, or how many cards you need to run it. https://huggingface.co/spaces/Vokturz/can-it-run-llm
You should be able to do inference on all 7b or smaller models with quantization.
Wow thank you I’ll look into it!
You can download 7B, 13B Q_8 models for such gpu. 30B Q_2 models would probably run out of memory.
This shows that larger models have lower perplexity (i.e. more coherent). You can run conversational models, but not those with infinite knowledge base.
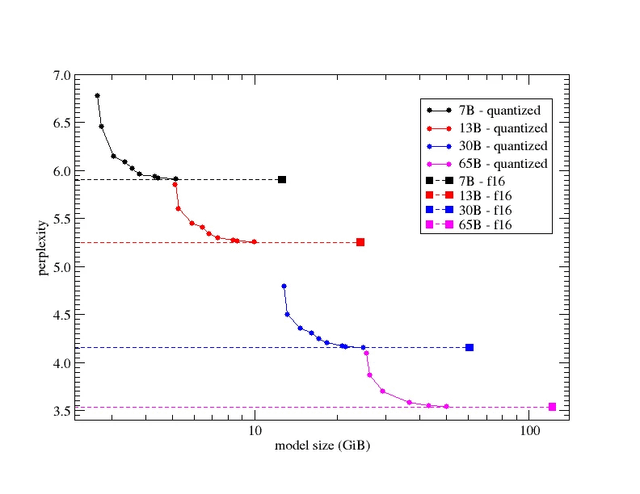
Most of the paid services that provide open-source models use 13B models (for $15 per month); you can run those for free on your card.
Someone else needs to recommend a tool to run models locally.
Question: What is the best self hosted coding assistant?
The (only) project i found, that does what i want:
It works ok for the most part. The problem i have with it is that inline completion is more annoying then helpful, because the AI only sees the last few lines that you wrote and therefore does not know the larger context of the project.
I also found this project, it looks promising. Has anyone tested it? Can you separate the server from the client?
Are there other projects that integrate well into an IDE?
Not yet. Tabby has context search on its roadmap:
I’ve had decent results with continue, it’s similar to copilot and actually works decently with local models lately:
Thanks for the suggestion, I tried it and the diff view is very good. The setup was not really easy for my local models, but after i set it up, it was really fast. The biggest problem with the tool is that the open source models are not that good, i tried if it could fix a bug in my code and it was only able to make it worse. On a more positive note, you at least do not need to copy all text over to another window and it is great for generating boilerplate code nearly flawlessly every time.
Yeah definitely need to still understand the open source limits, they’re getting pretty dam good at generating code but their comprehension isn’t quite there, I think the ideal is eventually having 2 models, one that determines the problem and what the solution would be, and another that generates the code, so that things like “fix this bug” or more vague questions like “how do I start writing this app” would be more successful
Where is the sweet spot for running CPU bound models? I’ve just started playing with llama.cpp but the big models do make the cores work pretty hard. Should I look at using quantisation or more fine tuned models for the tasks I care about (developer assistance mainly).
If you’re using llama.cpp chances are you’re already using a quantized model, if not then yes you should be. Unfortunately without crazy fast ram you’re basically limited to 7B models if you want any amount of speed (5-10 tokens/s)
Is there a standard for the suffixes? For example the OpenLlama models here: https://huggingface.co/SlyEcho/open_llama_7b_v2_gguf/tree/main have qN and and then a mix of K, M, 0 and 1 suffixes. The q I assume is the quantisation level but measured how? Does q2 mean t 2bits per weight? That seems very small - and what is it fixed float, integers?
Yeah so those are mixed, definitely not putting each individual weight to 2 bits because as you said that’s very small, i don’t even think it averages out to 2 bits but more like 2.56
You can read some details here on bits per weight: https://huggingface.co/TheBloke/LLaMa-30B-GGML/blob/8c7fb5fb46c53d98ee377f841419f1033a32301d/README.md#explanation-of-the-new-k-quant-methods
Unfortunately this is not the whole story either, as they get further combined with other bits per weight, like q2_k is Q4_K for some of the weights and Q2_K for others, resulting in more like 2.8 bits per weight
Generally speaking you’ll want to use Q4_K_M unless going smaller really benefits you (like you can fit the full thing on GPU)
Also, the bigger the model you have (70B vs 7B) the lower you can go on quantization bits before it degrades to complete garbage
I get an error when offloading the whole model to GPU
./build/bin/llama-cli -m ~/software/ai/models/deepseek-math-7b-instruct.Q8_0.gguf -n 200 -t 10 -ngl 31 -if
The relevant output is:
…
llama_model_load_from_file_impl: using device Vulkan0 (Intel® Iris® Xe Graphics (RPL-U)) - 7759 MiB free
…
print_info: file size = 6.84 GiB (8.50 BPW)
…
load_tensors: loading model tensors, this can take a while… (mmap = true) load_tensors: offloading 30 repeating layers to GPU load_tensors: offloading output layer to GPU load_tensors: offloaded 31/31 layers to GPU load_tensors: Vulkan0 model buffer size = 6577.83 MiB load_tensors: CPU_Mapped model buffer size = 425.00 MiB
…
ggml_vulkan: Device memory allocation of size 2013265920 failed ggml_vulkan: vk::Device::allocateMemory: ErrorOutOfDeviceMemory llama_kv_cache_init: failed to allocate buffer for kv cache llama_init_from_model: llama_kv_cache_init() failed for self-attention cache common_init_from_params: failed to create context with model ‘~/software/ai/models/deepseek-math-7b-instruct.Q8_0.gguf’ main: error: unable to load model
It seems to me that there is enough room for the model, but I don’t know what “Device memory allocation of size 2013265920” means.
I suppose that line means llama.cpp tried to allocate another chunk of memory, roughly 2GB and that failed because there wasn’t any memory left. I’m not sure about the details, maybe it’s the KV cache and additional stuff that is required for the computation aside from the model itself? Have you tried lowering the number of layers to offload to the iGPU and see if that works? Like lowering the value to
-ngl 20might leave additional space for other important things.Yeah I tested with lower numbers and it works, I just wanted to offload the whole model thinking it will work, 2GB it’s a lot. With other models it prints about 250MB when fails and if you sum up the model size it’s still well below the iGPU free memory so I dont get it… anyway, I was thinking about upgrading the memory to 32GB or may be 64GB but I hesitate because with models around 7GB and CPU only I get around 5 t/s and with 14GB 2-3 t/s, so I run one of around 30GB I guess it will get around 1 t/s? My supposition is that increasing RAM doesn’t increase performance per se, just let’s you upload bigger models to memory, so performance is approximately linear on model size… what do you think?
From what I know, I assume yes, the relation between model size and speed/performance should be linear. Maybe there is some additional small overhead making it a bit faster or slower than expected. But I’m really not an expert on the maths, so don’t trust me.
And maybe have a look at this bugreport: https://github.com/ggml-org/llama.cpp/issues/11332
I think it matches your situation. They resolve this by messing with the batch size and someone recommends not to use Vulkan on an iGPU.Oh great, thanks
I have two 3090 Turbo GPUs and it seems like oobabooga doesn’t split the load between the two cards when I try to run TheBloke/dolphin-2.7-mixtral-8x7b-AWQ.
Does anyone know how to make text generation webui use both cards? Do I need an nvlink between the two cards?
You shouldn’t need nvlink, I’m wondering if it’s something to do with AWQ since I know that exllamav2 and llama.cpp both support splitting in oobabooga
I think you’re right. Saw a post on Reddit basically mentioning the same things I’m seeing.
It looks like autoawq supports it but it might be an issue with how oobabooga implements it or something…
Do you usually have some other front-end over the model? I can run llama.cpp directly in interactive mode but the results are a little underwhelming. However there seem to be various front ends that get better results? Is this down to better prompting and parameter control? I’ve seen temperature mentioned in relation to ChatGPT but I have no idea what rope and yarn factors are for?
I use text-generation-webui mostly. If you’re only using GGUF files (llama.cpp), koboldcpp is a really good option
A lot of it is the automatic prompt formatting, there’s probably like 5-10 specific formats that are used, and using the right one for your model is very important to achieve optimal output. TheBloke usually lists the prompt format in his model card which is handy
Rope and yarn refer to extending the default context of a model through hacky (but functional) methods and probably deserve their own write up
Late to the party, I never got FOSAI working until I found LMStudio, but I have 2 questions:
-
Is there any way I could utilize my GPU, a Radeon RX6800M (12GB VRAM)? I got Mistral-7B doing 5 tokens/s but it’s all running on the CPU.
-
Is there any model specifically for programming questions? This could be of immense help to my projects without having to ask ChatGPT.
Have you tried the guide on AMD’s site? It looks like it’s for Windows, and I don’t know what you’re running. Plus, I use Ollama, so I probably can’t be of much help.
For programing, my favorite is Dolphin-Mixtral, but I’ve had good results with Dolphin-Mistral and Llama2.
I got a question about LMStudio! Is it FOSS, or is it just partly open?
On their website I see that they do have a github link, but I can’t identify the “main” project.
Looks like LMStudio is FOSS although I’m not 100% sure. What if does is allow you to run FOSAI models locally.
Yeah, that I understand. I was just curious, since currently I’m using ollama, which is fully FOSS, and some web UI to work with the LLMs in chat. but having it all in one place would be really nice.
I’ve heard some good things about LMStudio, but if it’s not FOSS, it’s not getting on my machine.
-




